GUID是对UUID标准的实现,援引百度百科的解释:
UUID含义是通用唯一识别码 (Universally Unique Identifier),这 是一个软件建构的标准,也是被开源软件基金会 (Open Software Foundation, OSF) 的组织应用在分布式计算环境 (Distributed Computing Environment, DCE) 领域的重要部分。
golang语言已有实现UUID的代码:仓库地址。
用这个库写如下代码:
1
2
3
4
|
u4, _ := uuid.NewV4()
fmt.Println(u4)
u5, _ := uuid.NewV5(uuid.NamespaceURL, []byte("nu7hat.ch"))
fmt.Println(u5)
|
会输出类似下面的输出(36个字符长度):
c28dc5c8-23b5-488a-4a5e-b496fc022e92
4443f977-ae75-5388-759f-93c0e0300805
除了UUID还有其他很多实现唯一ID发号器的方法。常见的,也是立马就能想到的是利用数据库的自增ID来实现。简单、暴力!但是在大并发环境下其性能堪忧。又是并发……
有使用两个数据库实例通过初始值和增长步长auto_increment一个生成奇数自增ID一个生成偶数自增ID,再加上事务达到生成唯一ID的做法,生成的ID可靠且有序,但是成本稍微高点。还有……万一表中的数据丢失会很麻烦。我正是在对golang学习项目IM消息处理中遇到的唯一ID的问题,相对IM的高效处理这种方式显然不太靠谱。
除此之外肯定还有其他的唯一id生成方式,本文要讲述的是当下被普遍采用的基于twitter的Snowflake算法实现。相比于UUID此算法生成的唯一ID长度更短且是数字类型的处理起来更高效,相比于数据库实现的方式最终生成的值友好性有些不足。不过该算法实现成本低,部署简单,灵活,相对时间有序当是目前GUID生成器首选。
Snowflake算法实现是twitter因自身业务需求(应对每秒成千上万的消息,还要有大致的顺序,用于前端显示排序)设计并开源的唯一id生成算法。
将参照以下图片(来源于网络)说明算法的原理:
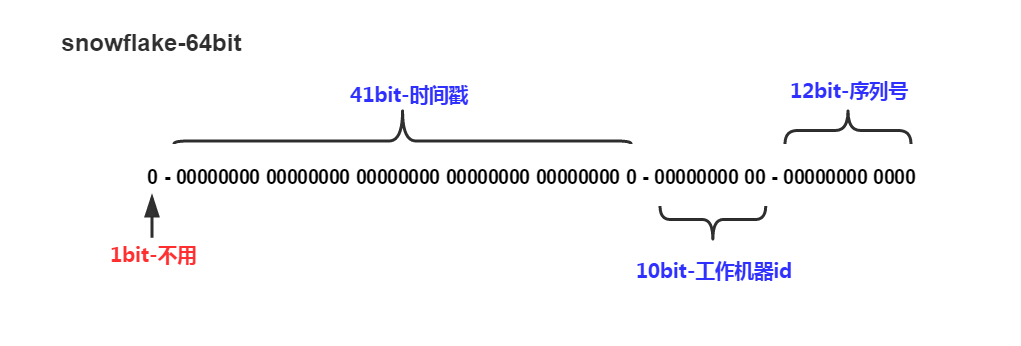
从结构来看生成的ID总占64bit,其中:
- 41位的时间戳:2^41/(24*3600*365*1000)=69(年)。也就是说时间精确到毫秒可以不间断使用69年。
- 10位的工作机器ID:2^10=1024(个),也就是为了避免单点故障而进行分布式部署时最多支持1024个节点。当然此参数可以按照实际需要进行调整,比如进一步的进行区域分组等。
- 12位的序列号:2^12=4096(个)。必须保正同一毫秒内唯一,可以使用其他文章中基于原子操作实现的唯一增长ID的方法获得。照此,理论上改算法每个节点每毫秒内可以生成4096个唯一ID。如果一毫秒内用完了4096个ID那么需要等待至下一毫秒。
- 最高位:为什么最高位不用?如果用了最高位那么以上2^42/(24*3600*365*1000)=139(年),可以使用139年。然而……由于最高位是符号位如果最高位不是恒为0将会产生负值那么ID的增长性就不存在了,也就是无法用于排序。
以下代码封装参照NSQ的内部实现完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
package context
//guid生成器 必须保证该结构体在程序中只初始化一次,否则有可能得到重复id
//依照snowflake算法得来
import (
"errors"
"strconv"
"sync"
"sync/atomic"
"time"
)
const (
//Poch ( 2017-05-27 16:52:35.250507739 +0800 CST ).UnixNano() / 1e6
Poch = 1495875155250
//WorkerIDBits WorkerId所占的位
WorkerIDBits = uint64(10)
//SenquenceBits 序列号占的位
SenquenceBits = uint64(12)
//WorkerIDShift 参照
WorkerIDShift = SenquenceBits
//TimeStampShift 参照
TimeStampShift = SenquenceBits + WorkerIDBits
//SequenceMask 最大序列号值 4095(4096个)
SequenceMask = int64(-1) ^ (int64(-1) << SenquenceBits)
//MaxWorker 最大客户端标志值 1023(1024个)
MaxWorker = int64(-1) ^ (int64(-1) << WorkerIDBits)
)
//GUID GUID定义
type GUID struct {
sync.Mutex
//Sequence 序列号
Sequence int64
//lastTimestamp 上一次时间戳
lastTimeStamp int64
//lastID 上一次生成的id
lastID int64
//WorkID
WorkID int64
}
//NewGUID 获取一个GUID对象
func NewGUID(workID int64) (*GUID, error) {
var g *GUID
if workID > MaxWorker {
return nil, errors.New("工作进程id超出最大值:" + strconv.FormatInt(MaxWorker, 10))
}
g = new(GUID)
return g, nil
}
//milliseconds 获得当前毫秒时间
func (g *GUID) milliseconds() int64 {
return time.Now().UnixNano() / 1e6
}
//NextID 获取一个GUID
func (g *GUID) NextID() (int64, error) {
var ts int64
var err error
g.Lock()
defer g.Unlock()
ts = g.milliseconds()
if ts == g.lastTimeStamp {
g.Sequence = (g.Sequence + 1) & SequenceMask
if g.Sequence == 0 {
ts = g.timeStamp(ts)
}
} else {
g.Sequence = 0
}
if ts < g.lastTimeStamp {
err = errors.New("时钟过期")
return 0, err
}
g.lastTimeStamp = ts
ts = (ts-Poch)<<TimeStampShift | g.WorkID<<WorkerIDShift | g.Sequence
return ts, nil
}
//timeStamp 获取一个可用时间基数
func (g *GUID) timeStamp(lastTimeStamp int64) int64 {
ts := g.milliseconds()
for {
if ts < lastTimeStamp {
ts = g.milliseconds()
} else {
break
}
}
return ts
}
//GetIncreaseID 并发环境下生成一个增长的id,按需设置局部变量或者全局变量
func (g *GUID) GetIncreaseID(ID *uint64) uint64 {
var n, v uint64
for {
v = atomic.LoadUint64(ID)
n = v + 1
if atomic.CompareAndSwapUint64(ID, v, n) {
break
}
}
return n
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import (
"bytes"
"fmt"
"regexp"
"strings"
"time"
"im/context"
"github.com/nu7hatch/gouuid"
)
func main() {
G, _ := context.NewGUID(1)
var id int64
for i := 0; i < 10000; i++ {
id, _ = G.NextID()
fmt.Println(id)
}
}
|
以上输出大致如下:
9064240476324302
9064240476324303
9064240476324304
9064240476324305
9064240476324306
9064240476324307
9064240476324308
...