线网一个客户轨迹服务出现 grpc 请求超时,设置客户端超时时间到6秒才差不多可以正常返回,这是一个严重的性能问题。监控面板查看服务占用资源也是正常的,重启服务后恢复正常,但是运行大约20个小时之后出现类似问题。决定利用 pprof 分析一下服务运行状态。记录之。
在使用 pprof 之前安装graphviz,以获得更优的视图展示支持。
1
2
|
# mac
brew install graphviz
|
代码中添加 golang 性能分析,通过 8080 端口暴露访问。确保服务的 8080 端口可被访问,比如在 k8s 中需要在 deployment 中指定开启 8080 端口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import (
"log"
"net/http"
_ "net/http"
// ...
)
func main() {
go func() {
log.Println(http.ListenAndServe("0.0.0.0:8080", nil))
}()
cmd.Execute()
}
|
启动采样。
1
|
go tool pprof -http=:1234 http://address:8080/debug/pprof/profile?seconds=30
|
采样完成后自动打 http://localhost:1234/。
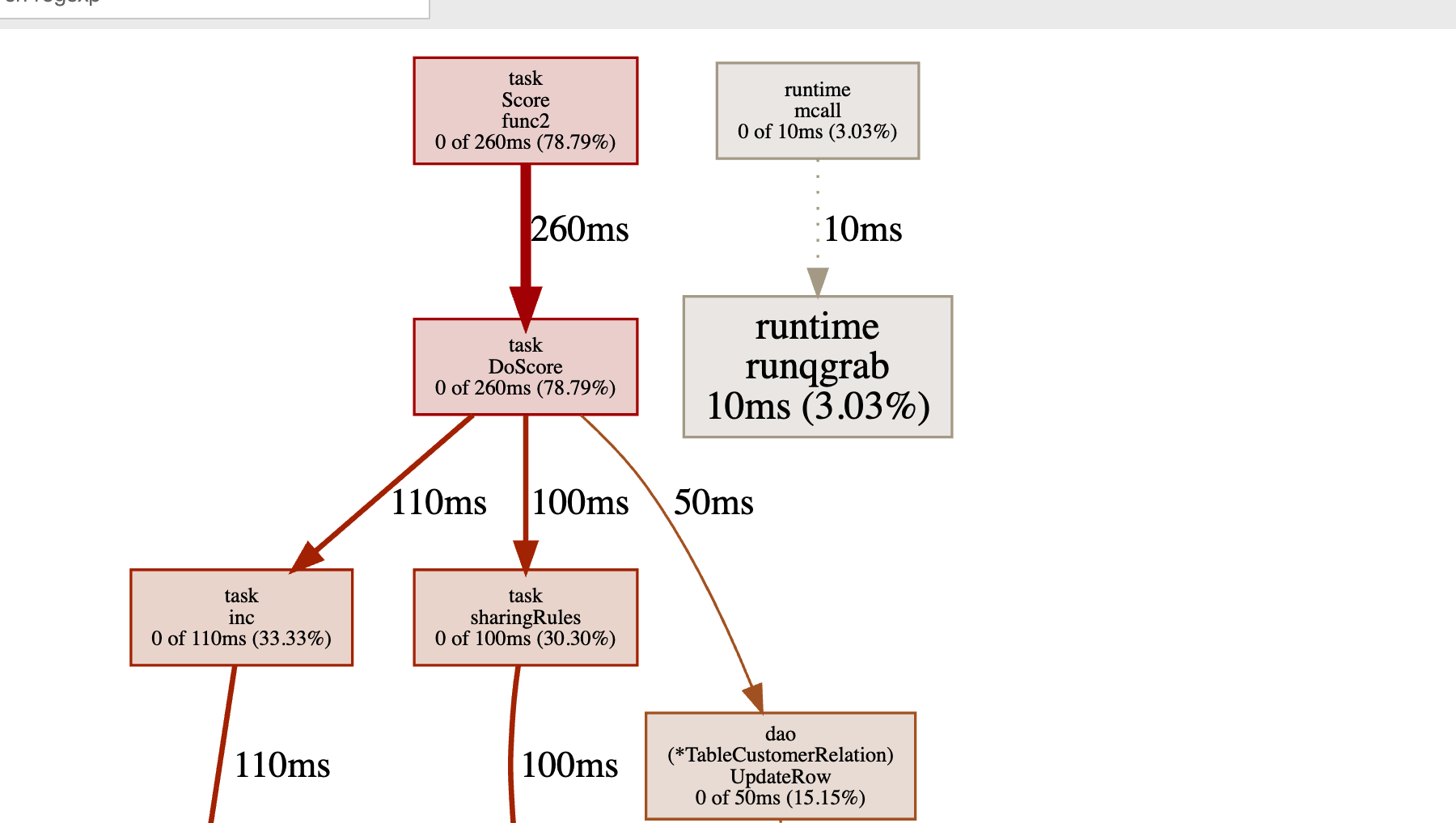 ◎ cpu profile 30秒采样结果
◎ cpu profile 30秒采样结果
从图中可以看出耗时调用栈,task.Sorce 方法为起始的处理耗时很多,其余几乎没有被采样。
进一步在VIEW中通过火焰图产看:
 ◎ cpu profile 30秒采样火焰图展示
◎ cpu profile 30秒采样火焰图展示
可以看出两个数据库操作方法GetRowsShareTimeInterval和GetActionCountByModules占用了大量的 cpu 时间。
回查源码,此逻辑是通过 go-micro 事件接收一个定时任务然后启动一个协程遍历一个客户表。先取出 1000 条客户数据然后为每一个客户启动一个协程分别执行一系列的计分操作。每一个计分过程中对数据库进行了多次统计查询,计分完毕后更新客户评分。该任务执行时启动 1000 个左右的协程占用大量的 cpu 时间,导致 grpc 服务协程得不到及时调度。
浏览器打开http://address:8080/debug/pprof/如下:
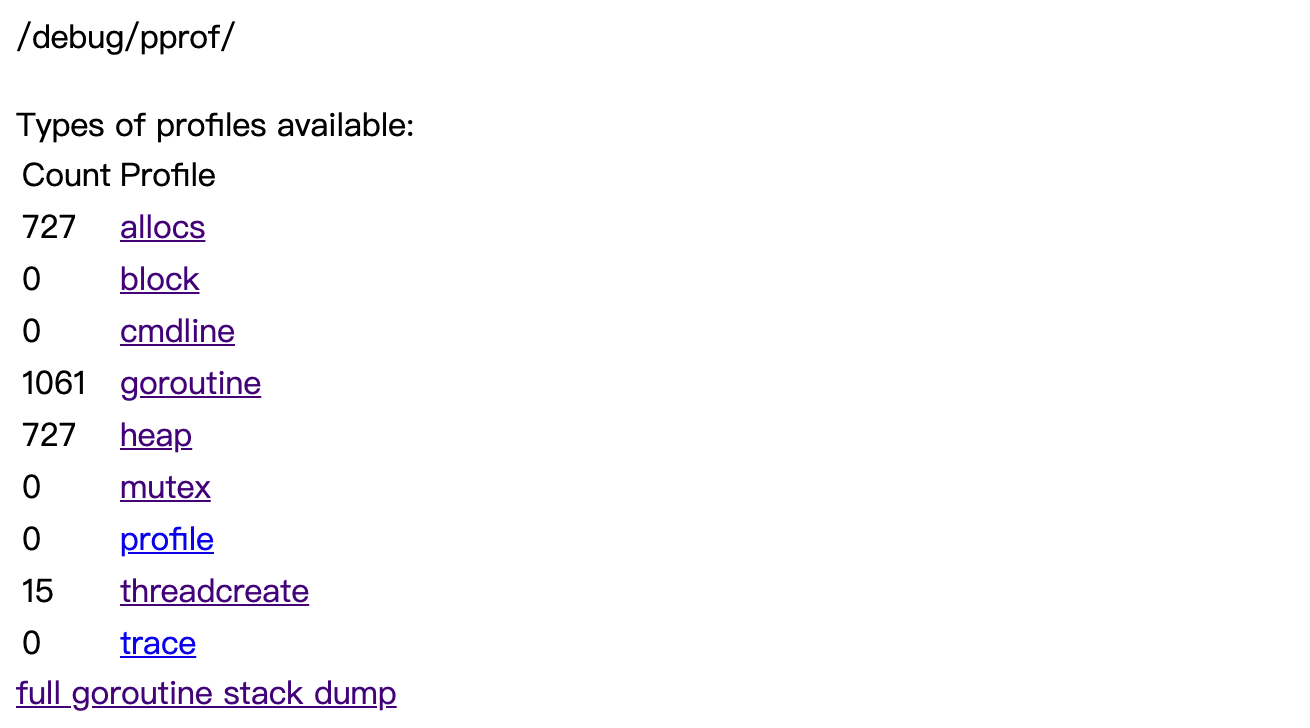 ◎ debug/pprof 预览
◎ debug/pprof 预览
显而易见由于 goroutine 的公平调度,导致 grpc 处理协程没有被及时调度。可以想到的解决方法有:
- 尝试优化计分过程使得单个计分任务执行时间缩短,进而缩短整个计分过程的时间。鉴于业务逻辑的复杂度改动成本比较大,而且就算优化好了如果数据体量上去执行时间还是得不到保证。
- 直接将计分任务分离除去单独启动而不是作为一个协程与 grpc 服务运行在一起。这个看起来是最直接有效的办法。成本在于运行运维变更成本以及后期更新问题上。
- 是否可以优先调度 grpc 服务协程?goroutine 的调度本身不支持优先调度设置, 可以通过 runtime.LockOSThread() 将协程绑定到当前内核线程上。由于该协程总是在这个内核线程上被调度。所以会获得更多的 cpu 时间从而达到
优先调度的效果,但是子协程不会继承这个设定。也就是说我们没法简单的将计分父协程绑定到一个内核上使得其他 grpc 服务协程尽可能的在其他内核线程运行。
- 尝试控制任务处理的协程数量,比如控制在 10 个协程以内,从本业务来说只需要最终完成计分操作即可,至于何时完成不是很重要。
经过权衡分析决定采用最后一种方式。变更前的Score方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
//Score 客户推荐指数计算定时任务逻辑
func Score() {
// 遍历客户表
com.Log.Info("==========>开始对遍历客户信息,进行推荐指数计算", time.Now().Format(t.TimeFormat))
defer func() {
com.Log.Info("=================>客户推荐指数任务执行完毕", time.Now().Format(t.TimeFormat))
}()
var limit uint64 = 1000
var offset uint64 = 0
var wg = &sync.WaitGroup{}
for {
// 取出数据
rs, err := dao.TbCustomerRelation.RangeUserCustomerList(limit, offset, "uid", "crm_id")
if err != nil && err != dbr.ErrNotFound {
com.Log.Error("数据库读写失败", err)
return
}
// 退出数据循环读取
if len(rs) == 0 {
return
}
for _, v := range rs {
wg.Add(1)
go func(v *entity.CustomerRelation) {
var finish = make(chan bool, 1)
// 很复杂的计分操作
DoScore(v.UID, v.CrmID, finish)
<-finish
close(finish)
wg.Add(-1)
}(v)
}
wg.Wait()
offset = limit + offset
}
}
|
变更后的Score方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// Score 客户推荐指数计算定时任务逻辑
func Score() {
// 遍历客户表
com.Log.Info("==========>开始对遍历客户信息,进行推荐指数计算", time.Now().Format(t.TimeFormat))
// 任务协程数量---这里的数量不能太多要控制在一个合理范围内,否则其他 grpc 等服务协程得不到调度,会出现服务拒绝的情况
var taskNum = 2
var dataCH = make(chan *entity.CustomerRelation, taskNum)
ctx, cancel := context.WithCancel(context.Background())
// 任务协程
taskWorker := func(ctx context.Context) {
for {
select {
case v, ok := <-dataCH:
if ok && v != nil {
DoScore(v.UID, v.CrmID, nil)
}
case <-ctx.Done():
return
}
}
}
// 启动指定数量的协程
for i := 0; i < taskNum; i++ {
go taskWorker(ctx)
}
var limit uint64 = 1000
var offset uint64 = 0
for {
// 取出数据
rs, err := dao.TbCustomerRelation.RangeUserCustomerList(limit, offset, "uid", "crm_id")
if err != nil && err != dbr.ErrNotFound {
com.Log.Error("数据库读写失败", err)
break
}
// 退出数据循环读取
if len(rs) == 0 {
break
}
for _, v := range rs {
dataCH <- v
}
offset = limit + offset
}
close(dataCH)
cancel()
com.Log.Info("=================>客户推荐指数任务执行完毕", time.Now().Format(t.TimeFormat))
}
|
事实证明控制协程数量可以修复超时问题。